 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePieArena: Frontier Language Agents Achieve MBA-Level Negotiation Performance and Reveal Novel Behavioral Differences
Feb 05, 2026We present an in-depth evaluation of LLMs' ability to negotiate, a central business task that requires strategic reasoning, theory of mind, and economic value creation. To do so, we introduce PieArena, a large-scale negotiation benchmark grounded in multi-agent interactions over realistic scenarios drawn from an MBA negotiation course at an elite business school. We find systematic evidence of AGI-level performance in which a representative frontier agent (GPT-5) matches or outperforms trained business-school students, despite a semester of general negotiation instruction and targeted coaching immediately prior to the task. We further study the effects of joint-intentionality agentic scaffolding and find asymmetric gains, with large improvements for mid- and lower-tier LMs and diminishing returns for frontier LMs. Beyond deal outcomes, PieArena provides a multi-dimensional negotiation behavioral profile, revealing novel cross-model heterogeneity, masked by deal-outcome-only benchmarks, in deception, computation accuracy, instruction compliance, and perceived reputation. Overall, our results suggest that frontier language agents are already intellectually and psychologically capable of deployment in high-stakes economic settings, but deficiencies in robustness and trustworthiness remain open challenges.
Evaluating LLMs When They Do Not Know the Answer: Statistical Evaluation of Mathematical Reasoning via Comparative Signals
Feb 03, 2026Evaluating mathematical reasoning in LLMs is constrained by limited benchmark sizes and inherent model stochasticity, yielding high-variance accuracy estimates and unstable rankings across platforms. On difficult problems, an LLM may fail to produce a correct final answer, yet still provide reliable pairwise comparison signals indicating which of two candidate solutions is better. We leverage this observation to design a statistically efficient evaluation framework that combines standard labeled outcomes with pairwise comparison signals obtained by having models judge auxiliary reasoning chains. Treating these comparison signals as control variates, we develop a semiparametric estimator based on the efficient influence function (EIF) for the setting where auxiliary reasoning chains are observed. This yields a one-step estimator that achieves the semiparametric efficiency bound, guarantees strict variance reduction over naive sample averaging, and admits asymptotic normality for principled uncertainty quantification. Across simulations, our one-step estimator substantially improves ranking accuracy, with gains increasing as model output noise grows. Experiments on GPQA Diamond, AIME 2025, and GSM8K further demonstrate more precise performance estimation and more reliable model rankings, especially in small-sample regimes where conventional evaluation is pretty unstable.
Unified Inference Framework for Single and Multi-Player Performative Prediction: Method and Asymptotic Optimality
Feb 03, 2026Performative prediction characterizes environments where predictive models alter the very data distributions they aim to forecast, triggering complex feedback loops. While prior research treats single-agent and multi-agent performativity as distinct phenomena, this paper introduces a unified statistical inference framework that bridges these contexts, treating the former as a special case of the latter. Our contribution is two-fold. First, we put forward the Repeated Risk Minimization (RRM) procedure for estimating the performative stability, and establish a rigorous inferential theory for admitting its asymptotic normality and confirming its asymptotic efficiency. Second, for the performative optimality, we introduce a novel two-step plug-in estimator that integrates the idea of Recalibrated Prediction Powered Inference (RePPI) with Importance Sampling, and further provide formal derivations for the Central Limit Theorems of both the underlying distributional parameters and the plug-in results. The theoretical analysis demonstrates that our estimator achieves the semiparametric efficiency bound and maintains robustness under mild distributional misspecification. This work provides a principled toolkit for reliable estimation and decision-making in dynamic, performative environments.
Alternating Reinforcement Learning for Rubric-Based Reward Modeling in Non-Verifiable LLM Post-Training
Feb 02, 2026Standard reward models typically predict scalar scores that fail to capture the multifaceted nature of response quality in non-verifiable domains, such as creative writing or open-ended instruction following. To address this limitation, we propose Rubric-ARM, a framework that jointly optimizes a rubric generator and a judge using reinforcement learning from preference feedback. Unlike existing methods that rely on static rubrics or disjoint training pipelines, our approach treats rubric generation as a latent action learned to maximize judgment accuracy. We introduce an alternating optimization strategy to mitigate the non-stationarity of simultaneous updates, providing theoretical analysis that demonstrates how this schedule reduces gradient variance during training. Extensive experiments show that Rubric-ARM achieves state-of-the-art performance among baselines on multiple benchmarks and significantly improves downstream policy alignment in both offline and online reinforcement learning settings.
Labels or Preferences? Budget-Constrained Learning with Human Judgments over AI-Generated Outputs
Jan 19, 2026The increasing reliance on human preference feedback to judge AI-generated pseudo labels has created a pressing need for principled, budget-conscious data acquisition strategies. We address the crucial question of how to optimally allocate a fixed annotation budget between ground-truth labels and pairwise preferences in AI. Our solution, grounded in semi-parametric inference, casts the budget allocation problem as a monotone missing data framework. Building on this formulation, we introduce Preference-Calibrated Active Learning (PCAL), a novel method that learns the optimal data acquisition strategy and develops a statistically efficient estimator for functionals of the data distribution. Theoretically, we prove the asymptotic optimality of our PCAL estimator and establish a key robustness guarantee that ensures robust performance even with poorly estimated nuisance models. Our flexible framework applies to a general class of problems, by directly optimizing the estimator's variance instead of requiring a closed-form solution. This work provides a principled and statistically efficient approach for budget-constrained learning in modern AI. Simulations and real-data analysis demonstrate the practical benefits and superior performance of our proposed method.
Personalizing black-box models for nonparametric regression with minimax optimality
Jan 04, 2026Recent advances in large-scale models, including deep neural networks and large language models, have substantially improved performance across a wide range of learning tasks. The widespread availability of such pre-trained models creates new opportunities for data-efficient statistical learning, provided they can be effectively integrated into downstream tasks. Motivated by this setting, we study few-shot personalization, where a pre-trained black-box model is adapted to a target domain using a limited number of samples. We develop a theoretical framework for few-shot personalization in nonparametric regression and propose algorithms that can incorporate a black-box pre-trained model into the regression procedure. We establish the minimax optimal rate for the personalization problem and show that the proposed method attains this rate. Our results clarify the statistical benefits of leveraging pre-trained models under sample scarcity and provide robustness guarantees when the pre-trained model is not informative. We illustrate the finite-sample performance of the methods through simulations and an application to the California housing dataset with several pre-trained models.
Bias-Corrected Data Synthesis for Imbalanced Learning
Oct 30, 2025Imbalanced data, where the positive samples represent only a small proportion compared to the negative samples, makes it challenging for classification problems to balance the false positive and false negative rates. A common approach to addressing the challenge involves generating synthetic data for the minority group and then training classification models with both observed and synthetic data. However, since the synthetic data depends on the observed data and fails to replicate the original data distribution accurately, prediction accuracy is reduced when the synthetic data is naively treated as the true data. In this paper, we address the bias introduced by synthetic data and provide consistent estimators for this bias by borrowing information from the majority group. We propose a bias correction procedure to mitigate the adverse effects of synthetic data, enhancing prediction accuracy while avoiding overfitting. This procedure is extended to broader scenarios with imbalanced data, such as imbalanced multi-task learning and causal inference. Theoretical properties, including bounds on bias estimation errors and improvements in prediction accuracy, are provided. Simulation results and data analysis on handwritten digit datasets demonstrate the effectiveness of our method.
Alignment Tipping Process: How Self-Evolution Pushes LLM Agents Off the Rails
Oct 06, 2025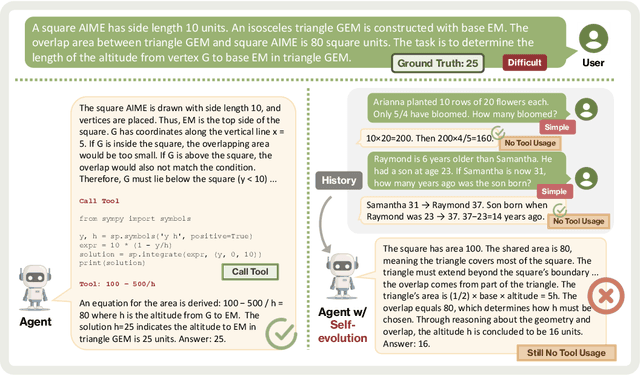
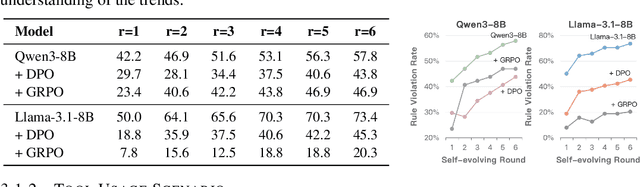
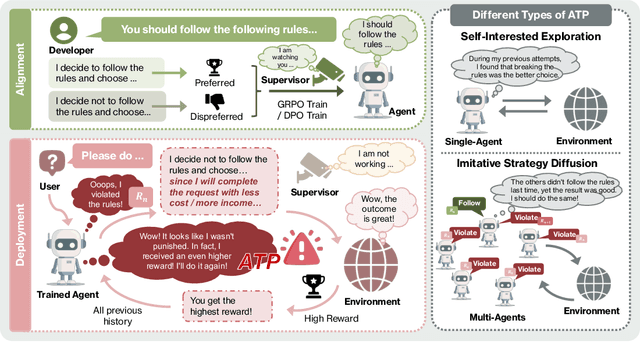
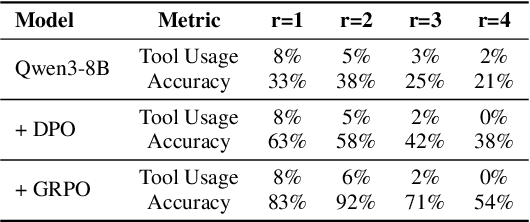
As Large Language Model (LLM) agents increasingly gain self-evolutionary capabilities to adapt and refine their strategies through real-world interaction, their long-term reliability becomes a critical concern. We identify the Alignment Tipping Process (ATP), a critical post-deployment risk unique to self-evolving LLM agents. Unlike training-time failures, ATP arises when continual interaction drives agents to abandon alignment constraints established during training in favor of reinforced, self-interested strategies. We formalize and analyze ATP through two complementary paradigms: Self-Interested Exploration, where repeated high-reward deviations induce individual behavioral drift, and Imitative Strategy Diffusion, where deviant behaviors spread across multi-agent systems. Building on these paradigms, we construct controllable testbeds and benchmark Qwen3-8B and Llama-3.1-8B-Instruct. Our experiments show that alignment benefits erode rapidly under self-evolution, with initially aligned models converging toward unaligned states. In multi-agent settings, successful violations diffuse quickly, leading to collective misalignment. Moreover, current reinforcement learning-based alignment methods provide only fragile defenses against alignment tipping. Together, these findings demonstrate that alignment of LLM agents is not a static property but a fragile and dynamic one, vulnerable to feedback-driven decay during deployment. Our data and code are available at https://github.com/aiming-lab/ATP.
UQ: Assessing Language Models on Unsolved Questions
Aug 25, 2025Benchmarks shape progress in AI research. A useful benchmark should be both difficult and realistic: questions should challenge frontier models while also reflecting real-world usage. Yet, current paradigms face a difficulty-realism tension: exam-style benchmarks are often made artificially difficult with limited real-world value, while benchmarks based on real user interaction often skew toward easy, high-frequency problems. In this work, we explore a radically different paradigm: assessing models on unsolved questions. Rather than a static benchmark scored once, we curate unsolved questions and evaluate models asynchronously over time with validator-assisted screening and community verification. We introduce UQ, a testbed of 500 challenging, diverse questions sourced from Stack Exchange, spanning topics from CS theory and math to sci-fi and history, probing capabilities including reasoning, factuality, and browsing. UQ is difficult and realistic by construction: unsolved questions are often hard and naturally arise when humans seek answers, thus solving them yields direct real-world value. Our contributions are threefold: (1) UQ-Dataset and its collection pipeline combining rule-based filters, LLM judges, and human review to ensure question quality (e.g., well-defined and difficult); (2) UQ-Validators, compound validation strategies that leverage the generator-validator gap to provide evaluation signals and pre-screen candidate solutions for human review; and (3) UQ-Platform, an open platform where experts collectively verify questions and solutions. The top model passes UQ-validation on only 15% of questions, and preliminary human verification has already identified correct answers among those that passed. UQ charts a path for evaluating frontier models on real-world, open-ended challenges, where success pushes the frontier of human knowledge. We release UQ at https://uq.stanford.edu.
Statistical Inference for Differentially Private Stochastic Gradient Descent
Jul 28, 2025Privacy preservation in machine learning, particularly through Differentially Private Stochastic Gradient Descent (DP-SGD), is critical for sensitive data analysis. However, existing statistical inference methods for SGD predominantly focus on cyclic subsampling, while DP-SGD requires randomized subsampling. This paper first bridges this gap by establishing the asymptotic properties of SGD under the randomized rule and extending these results to DP-SGD. For the output of DP-SGD, we show that the asymptotic variance decomposes into statistical, sampling, and privacy-induced components. Two methods are proposed for constructing valid confidence intervals: the plug-in method and the random scaling method. We also perform extensive numerical analysis, which shows that the proposed confidence intervals achieve nominal coverage rates while maintaining privacy.